
Hallo zusammen! Wir sind das Data Science Team von Innovaforge, wir beschäftigen uns mit LLM, generativen Netzwerken, insbesondere Sprachmodellen. In diesem Artikel teilen wir unsere Erfahrungen mit großen Sprachmodellen (LLMs), ihre Implementierung für die Verarbeitung von Unternehmensdaten und unsere Ergebnisse und Schlussfolgerungen.
Wir werden auch unseren Ansatz zur Nutzung von LLMs erläutern, die Retrieval Augmented Generation (RAG) Methode näher erläutern und Beispiele für den Einsatz von Chatbots auf den Unternehmensportalen unserer Kunden betrachten.
Was ist ein LLM?
Ein LLM oder Large Language Model (Großes Sprachmodell) ist ein neuronales Netzmodell, das auf großen Mengen an Textinformationen trainiert wird, um natürliche Sprache zu verstehen und zu erzeugen. Die Hauptaufgabe eines LLM ist es, Text als Input zu nehmen und darauf mit Text zu antworten.
Es ist wichtig zu beachten, dass LLMs durch die Länge der empfangenen Informationen (Kontext) begrenzt sind – die maximale Anzahl von Token, die das Modell in einem Aufruf verarbeiten kann. Ein Token ist eine sprachliche Einheit, mit der das Modell arbeitet. Meistens enthält ein Token 2-4 Buchstaben. Der Kontext in Modellen hat in der Regel eine feste Länge, die in der Regel 4000 Token beträgt.
Bei der Arbeit mit LLMs stoßen wir nicht nur an Grenzen, was die Länge des Kontextes angeht: Die Verarbeitung von Unternehmensdaten bringt auch ihre eigenen Herausforderungen mit sich. Wir können keine Modelle verwenden, die nicht auf unseren Servern gehostet werden, da die Gefahr besteht, dass sensible Informationen nach außen dringen. Daher müssen wir diese Daten entweder maskieren oder Open-Source-Modelle verwenden und sie auf unseren Servern pflegen. Heute werden wir darüber sprechen, wie wir mit der zweiten Option gearbeitet haben.
Tatsache ist, dass nicht alle LLMs “out of the box” ideal für den Einsatz sind. Viele Modelle unterstützen die deutsche Sprache nur unzureichend oder verfügen nicht über das für bestimmte Aufgaben erforderliche Fachwissen. Off-Box-Modelle können auch Informationen duplizieren und sind anfällig für Halluzinationen, was die Qualität der Antworten mindert.
Um diese Probleme zu lösen, ist es möglich, Modelle auf Ihren eigenen Daten vorzutrainieren, aber das ist oft schwierig und teuer. Was kann man tun? Hier kommt Retrieval Augmented Generation (RAG) ins Spiel.
RAG für LLM: eine Alternative zur Vorschulung
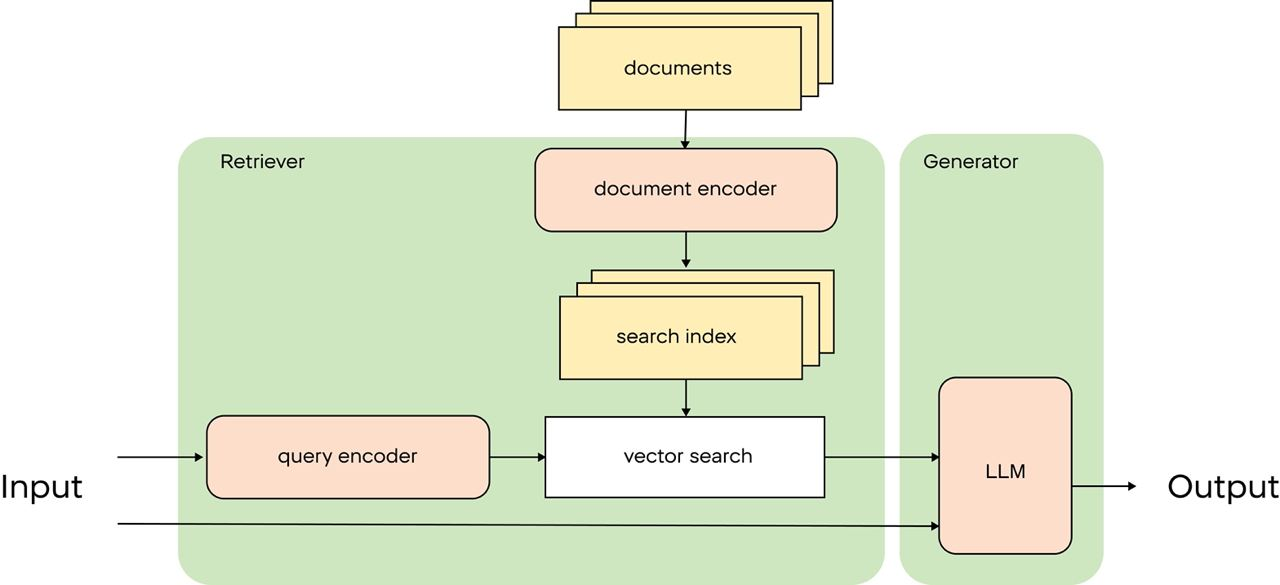
Als Alternative schlägt der RAG-Ansatz vor, relevante Informationen direkt im Kontext an den LLM zu übergeben. Wenn ein Benutzer zum Beispiel einen Verkaufsbericht für März 2024 wünscht, können wir relevante Dokumente finden, sie in Textform an den Kontext weitergeben und den LLM verwenden, um eine strukturierte Antwort zu generieren. Dieser Ansatz erhöht die Nützlichkeit des LLM in einer Unternehmensumgebung erheblich, da das Modell mit spezifischen und relevanten Daten arbeiten kann.
Großartig, aber wie macht man das? Der Aufbau einer einfachen RAG-Pipeline besteht aus drei Schritten:
- Dokumentenkonvertierung: Interne Dokumente (Anleitungen, Vorschriften, FAQs usw.) werden mit Hilfe von Einbettungsmodellen in Vektoren umgewandelt oder z. B. mit Elastic Search indiziert.
- Dokumentensuche: Wenn eine Benutzeranfrage eingeht, wird sie verwendet, um die nächstgelegenen Dokumente in der Datenbank zu finden.
- Antwortgenerierung: Der LLM generiert eine Antwort auf der Grundlage der abgerufenen Dokumente und der Anfrage des Benutzers.
Aber leider wird eine einfache RAG fast immer die Qualität der Suche und der Generierung Ihrer Daten nicht erfüllen. Dies liegt vor allem daran, dass Standardansätze nicht immer die Struktur der Daten berücksichtigen: Format, erforderliche Kontextlänge, Verteilung wichtiger Informationen über das Dokument und mehr.
Deshalb ist unsere Arbeit hier nicht zu Ende, sondern hat gerade erst begonnen: Wir haben lange mit Modifikationen von RAG-Systemen experimentiert, und endlich sind wir bereit, Ihnen mitzuteilen, was wir herausgefunden haben.
Verbesserung des RAG-Systems: Retrieval
RAG besteht aus zwei Teilen: Retrieval und Augmented Generation. Diese Teile können zusammen verbessert werden (siehe Hybrid RAG), aber es ist viel einfacher, sie getrennt zu verbessern. In diesem Artikel werden wir uns mit dem Retrieval beschäftigen.
Wir wollen das Retrieval verbessern, weil wir so wenig irrelevante Informationen wie möglich in den Kontext des Modells einfließen lassen wollen – irrelevante Informationen führen zu unnötigen Halluzinationen und falschen Antworten, und wenn wir kommerzielle Netzwerke (Open AI ChatGPT oder Google Gemini) verwenden, führt die Weitergabe von weniger Kontext auch zu Einsparungen bei den Token.
Der Retrieval-Teil einer komplizierten Pipeline besteht aus drei Schritten:
- Bearbeitung einer Benutzeranfrage (Query Expansion);
- Suche nach Dokumenten (Kontexten), um das Modell zu beantworten;
- Neueinstufung der abgerufenen Dokumente für eine genauere Ausgabe.
Schauen wir uns einmal an, wie wir jedes dieser Teile verbessert haben.
Query Expansion
Query Expansion ist ein Sammelbegriff für Techniken, bei denen es um die Erweiterung und Verfeinerung der Abfrage eines Benutzers geht. Diese Technik hilft, der ursprünglichen Benutzeranfrage mehr Kontext hinzuzufügen, indem sie potenzielle Antworten einbezieht, die dem System helfen, eine breitere Palette von Dokumenten abzudecken.

Wenn die ursprüngliche Anfrage zu mehrdeutig war, kann das Hinzufügen zusätzlicher Schlüsselwörter oder Phrasen, die auf den erwarteten Antworten basieren, die Suchergebnisse erheblich verbessern. Zum Beispiel können wir für die Suchanfrage “Urlaub” Antworten auf die Frage “Urlaubsvorbereitungen treffen”, “Urlaub verschieben” und viele ähnliche finden.
Schauen wir uns Beispiele für Algorithmen an, von den einfachsten bis zu den komplexeren.
Paraphrasierung mit LLM
Sehr oft stellen Nutzer eine Frage mit Tippfehlern oder minimalen Informationen. Nehmen wir das gleiche Beispiel, das wir bereits verwendet haben – die Anfrage “Urlaub”. Wir müssen verstehen, was der Nutzer will. Um dies zu tun, können wir einige Annahmen treffen und die Frage nicht mit “Urlaub” beantworten, sondern sie in “Wie macht man Urlaub?” umformulieren. Dann wird es für Frage-Antwort-Systeme viel einfacher sein, solche Fragen zu beantworten. Im Idealfall sollten Sie den Benutzer fragen, was er meint, aber die Arbeit mit dem Chatverlauf ist ein Thema für einen separaten Beitrag. Das Wichtigste ist, dass unser LLM beim Paraphrasieren helfen kann. Zum Beispiel mit der folgenden Promt:
Sie sind ein deutschsprachiger hilfsbereiter Assistent. Du hilfst dem technischen Support bei eingehenden Fragen. Die Benutzer schreiben nicht immer vollständige Fragen, Sie helfen immer, die eingehende Frage umzuformulieren und das Hauptproblem hervorzuheben.
Hier ist eine Benutzerfrage: “Urlaub”
Bitte schreibe die Frage um:

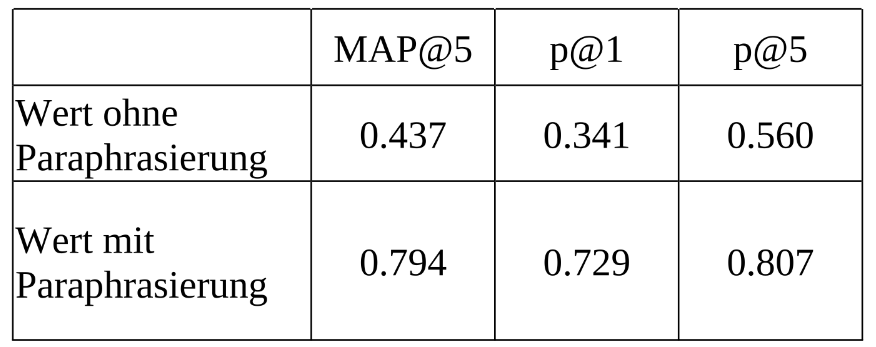
Wir verwenden verschiedene Prompts für verschiedene Datensätze, um falsch umschriebene Anfragen zu vermeiden. Außerdem wird die Notwendigkeit der Umschreibung mit Hilfe eines Klassifizierers vorab zu bewerten. Diese Methode hat sich erheblich auf die Qualität der Ergebnisse ausgewirkt:
SelfQuery
Diese Methode konzentriert sich auf die Extraktion und Nutzung von Metadaten aus der Abfrage selbst. Die Identifizierung von Elementen wie geografische Zugehörigkeit, Zeitrahmen oder spezifische Terminologie ermöglicht es dem System, die für die gestellte Frage relevantesten Dokumente genauer zu finden, während die Extraktion numerischer Werte aus der Abfrage einen direkten Vergleich ermöglicht.
Das Schema funktioniert wie folgt: Wir extrahieren Schlüsselwörter und Werte aus der Abfrage mit Hilfe der Promt, nach denen wir die Daten in der Datenbank weiter filtern können.

Diese Methode ist gut geeignet, wenn die Abfragen sehr detaillierte Informationen enthalten, die reich an Einzelheiten und vor allem an Zahlen sind. Ihr großer Vorteil ist, dass die Auswahl der Metadaten mit Hilfe eines neuronalen Netzes erfolgt und daher auch bei Tippfehlern und Synonymen in der Abfrage funktioniert.
Leider hat diese Methode bei uns nicht funktioniert, da unsere Abfragen nur wenige Metadaten enthalten und im Allgemeinen recht kurz sind: In unserem Beispiel über Urlaub wurde in den Metadaten die Kategorie der Abfrage (“Urlaub”) hervorgehoben, und die anschließende Umformulierung der Abfrage (eingebettet in die Promt) führte zu einer leeren Eingabeaufforderung. Es gab auch keine Zahlen, die wir zum Vergleich in unseren Abfragen verwenden konnten.
Wenn Sie ein Open-Source-Modell verwenden, kann es außerdem sein, dass Metadaten nicht gut hervorgehoben und Vorlagen nicht gut befolgt werden, was ebenfalls ein Nachteil dieser Methode ist.
Wir haben uns entschieden, SelfQuery nicht zu verwenden, zumindest nicht in dem bestehenden Projekt, aber diese Methode sieht sehr nützlich für die Verwendung in Projekten zur Immobiliensuche auf der Grundlage bestimmter Filter aus.
FLARE (Vorausschauende aktive Abfrage)
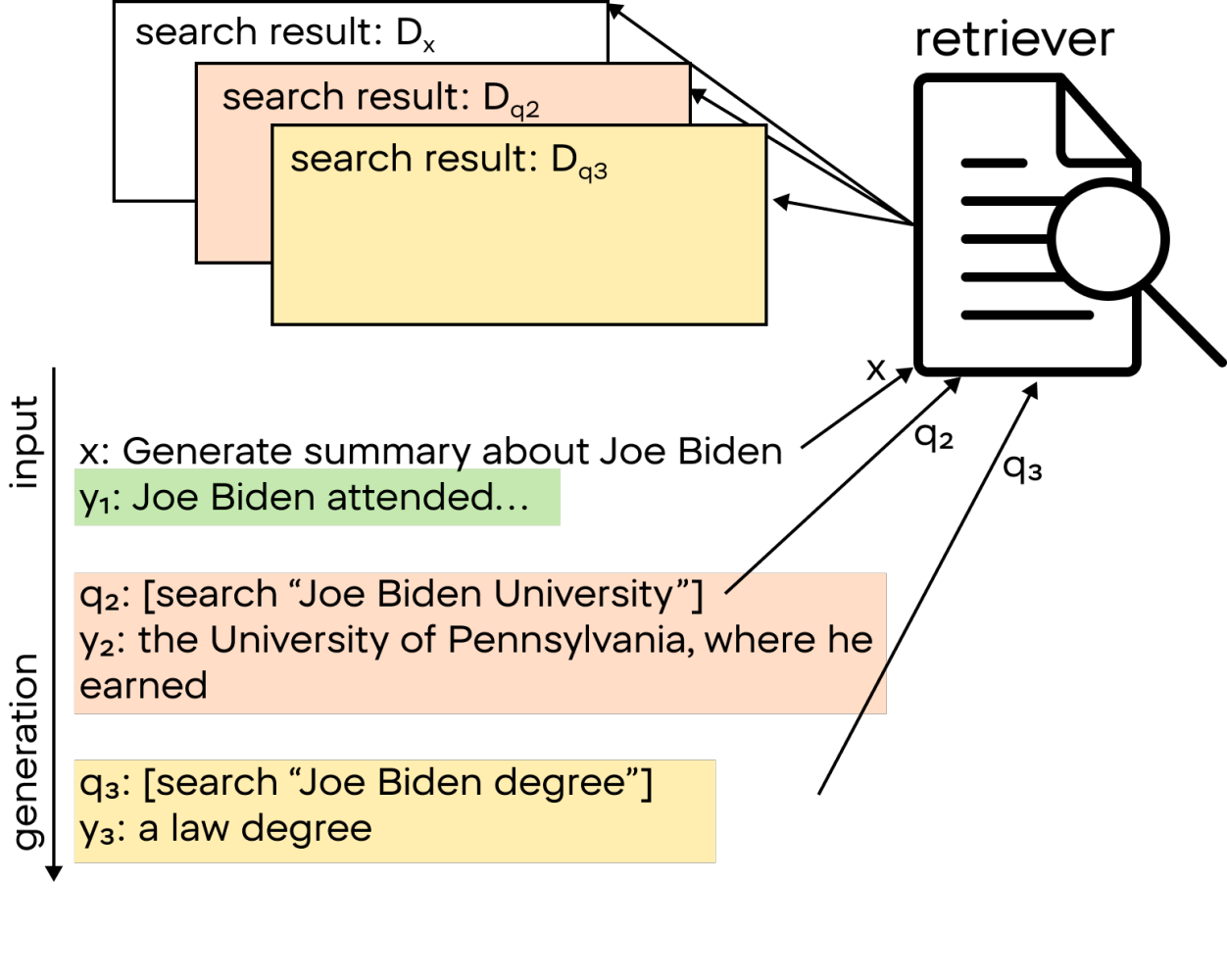
Diese Technik umfasst einen Mechanismus zur erneuten Suche, der aktiviert wird, wenn das LLM bei der Generierung von Antworten nicht zuverlässig ist. Wir messen das Vertrauen des Modells anhand der Logit-Verteilung der Verlustfunktion am Ausgang des neuronalen Netzes. Vereinfacht ausgedrückt handelt es sich dabei um die “Werte” der Antworten des Netzes – wenn viele Antworten ähnliche Werte aufweisen, dann ist das Modell in seiner Antwort nicht sicher. Wenn es zum Beispiel bei der Erstellung einer LLM-Antwort über Pr. Bidens Biografie anfängt zu zweifeln, welche Universität er besucht hat (dies wird verfolgt, wenn die Wahrscheinlichkeit der potenziellen Antwort-Token abnimmt). Das System sendet eine Anfrage an den LLM, um zu klären, wo er studiert hat, und fährt von dort aus fort, eine Antwort zu generieren. Dies wird so lange fortgesetzt, bis ein Stopp-Token erzeugt wird.
Obwohl wir die Anzahl der maximalen Wiederholungen des “Such-Generierungs”-Zyklus begrenzen können, vergeudet dieser Ansatz viel Zeit und Rechenleistung mit wiederholten Suchvorgängen und Pausen bei der Generierung. Außerdem neigt das Modell dazu, sich weit vom Thema zu entfernen. Bei Fragen zu Feiertagen neigt es dazu, darüber nachzudenken, was ein Feiertag ist, und die Frage nicht zu beantworten, so dass wir beschlossen haben, diesen Ansatz bei unseren Daten nicht zu verwenden.
Diese Methode eignet sich gut für kreativere Aufgaben wie das Schreiben von Artikeln, Geschichten und Aufsätzen. Wenn Ihre geschäftliche Aufgabe eine gewisse kreative Freiheit beinhaltet, kann diese Methode äußerst nützlich sein.
Die Methoden der Abfrageerweiterung, mit Ausnahme der Paraphrasierung, sind in unserer Aufgabe nicht anwendbar, aber in anderen Fällen können sie bedeutende Ergebnisse bringen. Sie sollten diese Methoden also noch testen, und wir werden zu einer anderen Stufe übergehen – der Suchmaschine.
Suchmaschine mit LLM
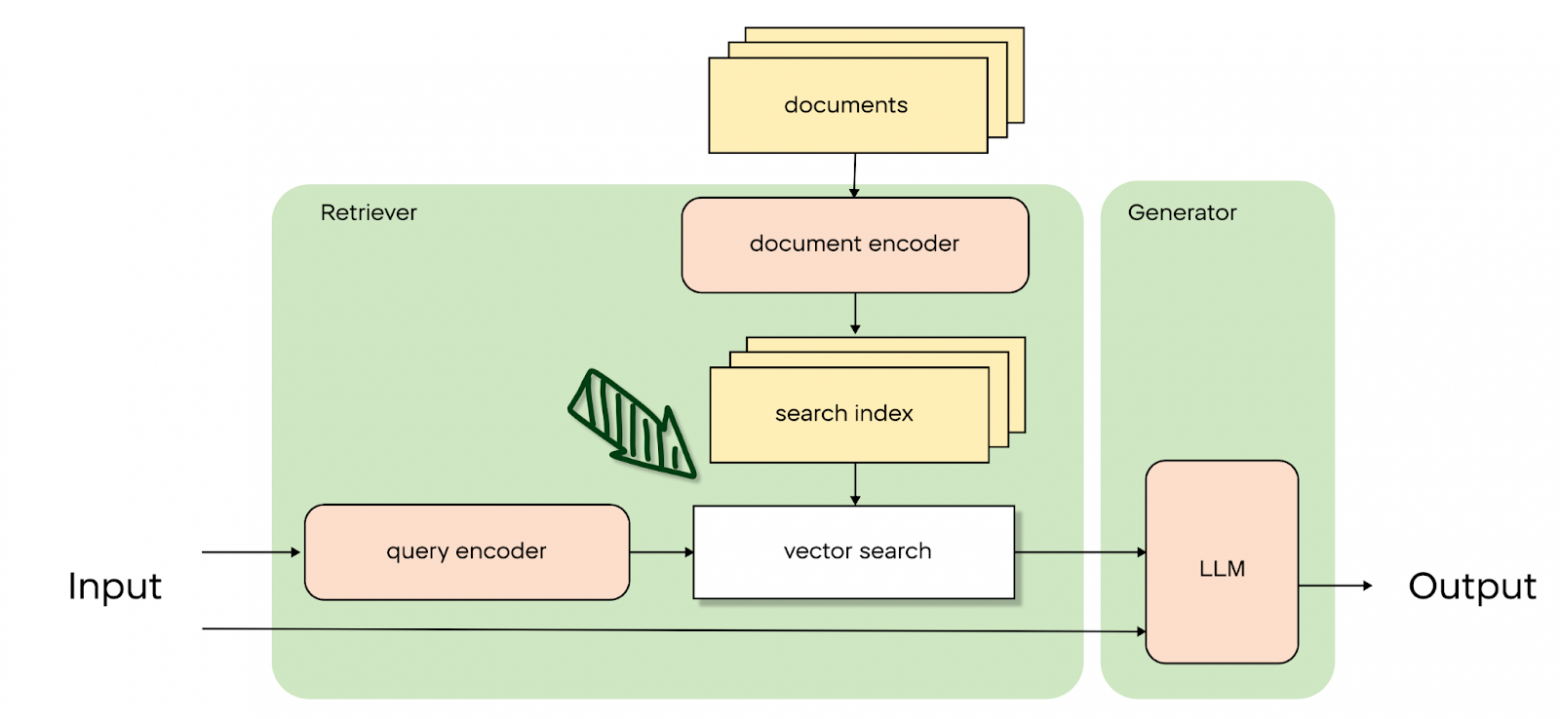
Sobald die Anfrage des Nutzers bearbeitet wurde, beginnt die Suche nach geeigneten Dokumenten. Hier können wir eine Parallele zu Suchmaschinen wie Google oder Bing ziehen. Aber in unserem Fall müssen wir nach Informationen über unsere internen Daten suchen, nicht über das gesamte Internet. Schauen wir uns nun an, wie wir nach Dokumenten suchen können, die der Anfrage entsprechen.
Vektorsuche
Die derzeit beliebteste Methode ist die Vektorsuche. Sie wird oft als semantische Suche bezeichnet. Das Wesen dieser Methode besteht darin, dass jeder Text als Vektor dargestellt werden kann – eine Reihe von Zahlen. Vektoren können als Bedeutungen von Texten miteinander verglichen werden. Je kleiner der Abstand zwischen den Vektoren ist, desto ähnlicher sind sich die verglichenen Texte in ihrer Bedeutung. Der Cosinusabstand wird zum Vergleich von Vektoren verwendet. Wir suchen also die Vektoren aller internen Dokumente und suchen die Dokumente, die der Suchanfrage des Benutzers am nächsten kommen, anhand des Kosinusabstandes. So entsteht die Idee der Vektorsuche.
Es gibt inzwischen viele spezialisierte Vektordatenbanken, und wir verwenden Qdrant. Mit dieser Technologie können Sie das, was wir oben beschrieben haben, sofort umsetzen.
Bei der Vektorsuche geht es vor allem darum, mit der Darstellung von Text als Vektoren zu experimentieren und die Suchqualität zu verbessern. Es gibt eine große Anzahl von Methoden, deren Qualität bei Ihren Daten von der Sprache, der durchschnittlichen Länge und dem Bereich abhängt. In unserer Arbeit haben wir clips/mfaq embeddings, intfloat/multilingual-e5-large und embeddings von LLaMA ausprobiert. Als bestes Vektorisierungstool erwies sich für uns multilingual-e5-large, aber Sie können den Finger am Puls der Zeit behalten, indem Sie die Rangliste hier durchstöbern und einen Embedder für die für Ihr Projekt relevante Aufgabe auswählen.
Andere Optionen
In der Tat gibt es so viele Möglichkeiten, zwei Texte miteinander zu vergleichen. Und man muss nicht einmal nur eine Sache verwenden, man kann sie auch kombinieren und zu einem Ensemble zusammenstellen.
BM25 und Volltextsuche
Die Verwendung der Vektorsuche bedeutet nicht, dass wir keine Schlagwortsuche verwenden können – es ist oft nützlich (insbesondere bei der Suche nach Dokumenten mit verschiedenen Akronymen und Begriffen), Informationen über die im Dokument vorkommenden Wörter zu verwenden.
Die Umsetzung des BM25 und Details können beispielsweise hier eingesehen werden.
Symmetrische Suche
Die Idee dieses Ansatzes ist einfach und funktioniert sehr gut: Wir suchen nicht nach Dokumenten, die für die Anfrage relevant sind, sondern nach anderen Fragen, die der Anfrage ähnlich sind. Wir holen sie aus der Datenbank, die während des Betriebs des Dienstes mit Hilfe der Fragestatistiken der Nutzer leicht wieder aufgefüllt wird.
Jede Frage in der Datenbank ist mit einem bestimmten Dokument verknüpft – es sind diese Dokumente, die wir als Ergebnis der symmetrischen Suche weitergeben. Auf diese Weise verbessern wir die Qualität der Suche nach relevantem Kontext bei häufig vorkommenden Fragen erheblich.
Wenn wir weiter gehen, können wir den Grad der “Häufigkeit” einer Anfrage bestimmen (z. B. durch Messung ihres Abstands zu anderen Fragen in der Datenbank) und, wenn diese Frage immer noch selten ist, können wir andere Suchalgorithmen durchführen.
SVM
SVM kann auch verwendet werden, um Dokumente auf der Grundlage ihrer Relevanz für eine Anfrage zu bewerten. Zu diesem Zweck wandeln wir die Einstufungstask in eine Klassifizierungstask um: relevante Dokumente werden als positive Klasse und irrelevante Dokumente als negative Klasse markiert. Auf diese Weise verwenden wir den SVM-Klassifikator, um Dokumente in relevante und irrelevante Dokumente zu unterteilen.
Für unsere Daten zeigte das Ensemble aus Vektorsuche + SVM-Retriever die beste Leistung.
Sie können verschiedene Optionen für Ihre Daten ausprobieren, die Langchain-Bibliothek bietet so viele Möglichkeiten.
Nachbearbeitung
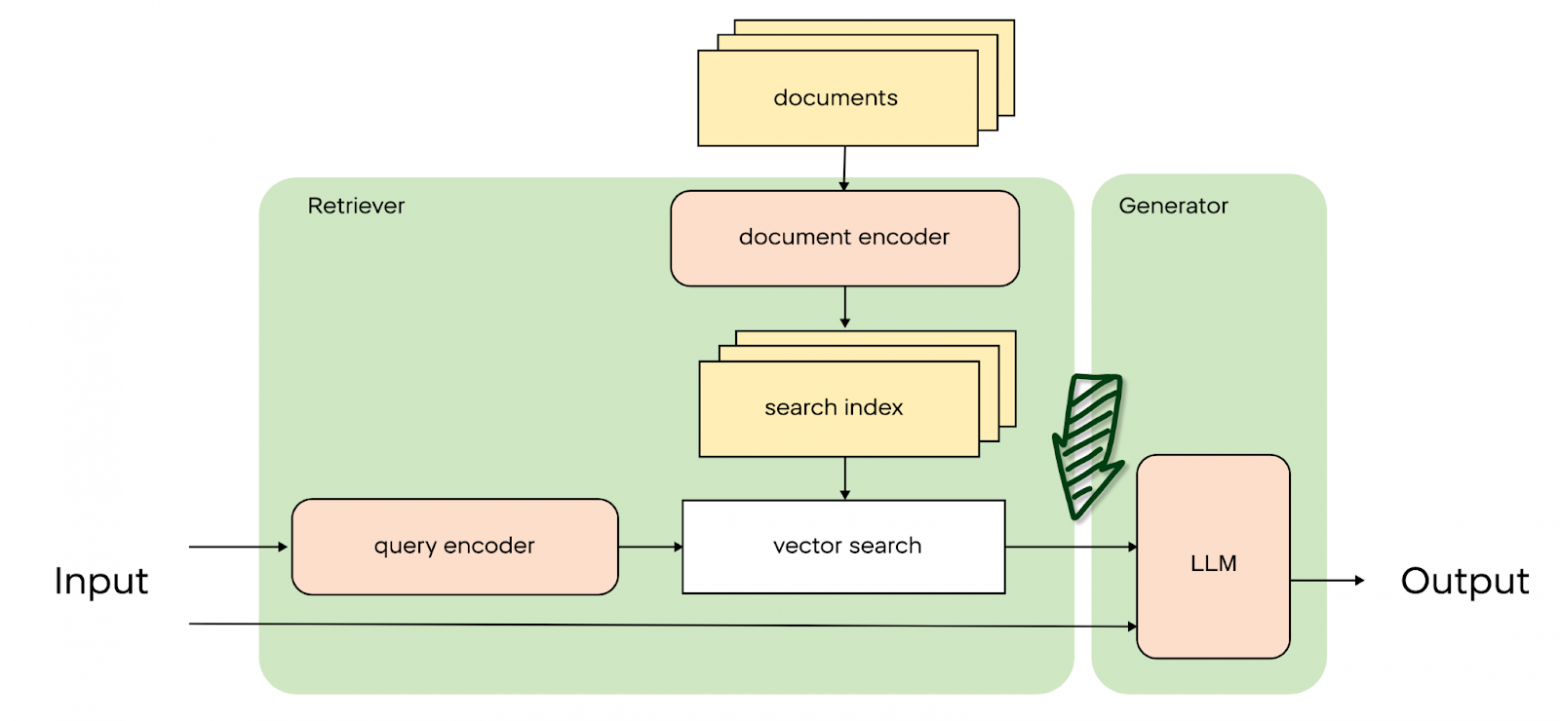
Die letzte Phase der Arbeit von Retriever in RAG-Systemen ist die Nachbearbeitung. In dieser Phase werden die abgerufenen Dokumente überarbeitet und neu geordnet, so dass die relevantesten Dokumente an den ersten Positionen stehen.
Die erste Einstufung der Dokumente durch den Retriever ist möglicherweise nicht ideal. Dies ist auf die Verwendung vereinfachter Algorithmen zurückzuführen, die nicht immer den Kontext der Suchanfrage berücksichtigen. Infolgedessen befinden sich relevante Dokumente möglicherweise nicht auf den ersten Plätzen, was die Sucheffizienz verringert. Es sei daran erinnert, dass wir aufgrund der begrenzten Größe des Modellkontexts nur eine begrenzte Anzahl von Dokumenten in unser LLM einspeisen können.
Um die Genauigkeit der Rangfolge der Dokumente zu verbessern, werden ausgefeiltere Methoden eingesetzt.
Cross-Encoder
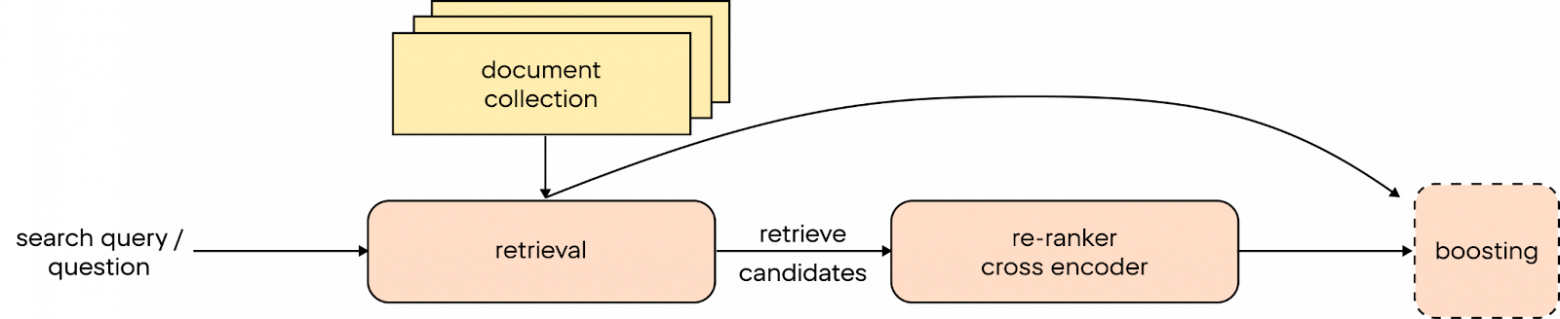
Es handelt sich um ein neuronales Netz, das darauf trainiert ist, den Grad der Nähe von Texten zueinander zu bewerten. Was ist der Unterschied zu unserer semantischen Suche? Riesig – Cross-Encoder ist ein komplexerer Algorithmus, der tiefe semantische Bedeutungen in Texten aufspürt. Dabei vergleicht er jedes gefundene Dokument mit der Suchanfrage des Benutzers und gibt eine numerische Ähnlichkeitsbewertung ab. Sie können nun die Dokumente auf der Grundlage des neuen Ergebnisses neu sortieren.
Auch die Werte der Zielkennzahlen haben sich dadurch deutlich verbessert:
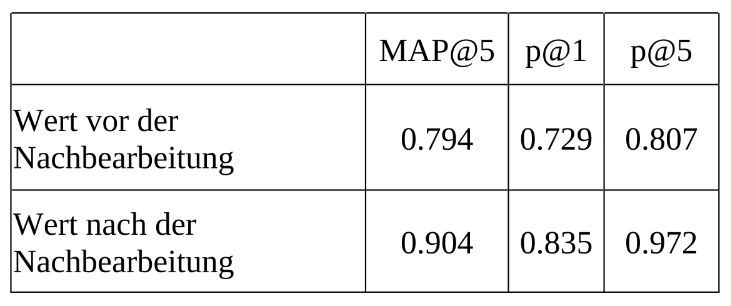
Was aber, wenn wir nicht nur nach Ähnlichkeit von Cross-Encodern, sondern auch von anderen sortieren wollen?
Boosting
Wir verwenden klassische ML. Zum Beispiel können wir Gradient Boosting trainieren. Diese Methode kombiniert viele schwache Modelle, um einen starken Vorhersagealgorithmus zu erstellen. In unserem Kontext kann Gradient Boosting verwendet werden, um die Relevanz jedes Dokuments für eine Anfrage genauer zu bestimmen: Ähnlichkeit aus Cross-Encoder, BM25 und anderen Scorern.
Die Nachbearbeitung ist ein wichtiger Schritt in RAG-Systemen, da sie die Suchqualität durch eine genauere Einstufung der Dokumente erheblich verbessern kann. Die Anwendung von Techniken wie Cross-Encoder und Gradient Boosting führt zu einem kontextbezogeneren und relevanteren Ranking der Dokumente.
Zusammenfassend
Das war’s für jetzt. Dieses Mal haben wir uns mehrere Varianten angesehen, wie wir die Suche nach relevanten Dokumenten für die RAGs verbessern können:
- Erste Verarbeitung der Benutzeranfrage mit Hilfe von Query-Expansion-Techniken: Paraphrasierung der Frage, Extraktion von Metadaten und Gewährleistung des Vertrauens des neuronalen Netzes in seine Generationen.
- Vektorsuche nach Dokumenten in der Datenbank.
- Nachträgliche Neueinstufung der abgerufenen Dokumente.
In den nächsten Artikeln werden wir über die Verbesserung der Generierung auf der Grundlage bereits gefundener Dokumente, die Überwachung von LLMs in Produktion, die Bekämpfung von Halluzinationen und mehr sprechen.