
Die rasante Entwicklung künstlicher Intelligenz, insbesondere von Chatbots wie ChatGPT, könnte in den kommenden Jahren auf ein großes Problem stoßen: Zwischen 2026 und 2032 könnten Technologieunternehmen nicht genügend menschliche Texte (Daten für KI) zur Verfügung haben. Das Training der Sprachmodelle stellt dann eine große Herausforderung dar.
Fakten
Tamay Besiroglu, einer der Autoren einer aktuellen Studie, beschreibt die Situation als einen “Goldrausch” im Bereich der KI. Ähnlich wie bei der Erschöpfung von natürlichen Ressourcen während eines Goldrausches, könnte der Vorrat an verfügbaren, von Menschen erstellten Textdaten zu Ende gehen, was den Fortschritt in der KI-Entwicklung erheblich verlangsamen könnte.
Technologiegiganten wie OpenAI und Google konkurrieren bereits heute heftig um hochwertige Daten, die sie zum Training ihrer Sprachmodelle benötigen. Sie schließen große Verträge mit Plattformen wie Reddit und verschiedenen Nachrichtenagenturen ab, um Zugang zu großen Mengen an Textdaten zu erhalten.
Was sagen Experten?
Experten warnen jedoch, dass der Strom an neuen Blogs, Nachrichtenartikeln und Kommentaren in sozialen Medien in Zukunft möglicherweise nicht mehr ausreichen wird, um den wachsenden Bedarf an KI-Daten zu decken.
Dies stellt die Entwickler vor eine schwierige Entscheidung: Sollen sie vertrauliche Daten wie persönliche Korrespondenz verwenden, was erhebliche ethische und rechtliche Probleme aufwirft, oder sollen sie auf synthetische Daten zurückgreifen, die von Chatbots selbst erstellt werden? Letzteres birgt jedoch die Gefahr, dass die Qualität und Genauigkeit der KI-Systeme abnimmt.
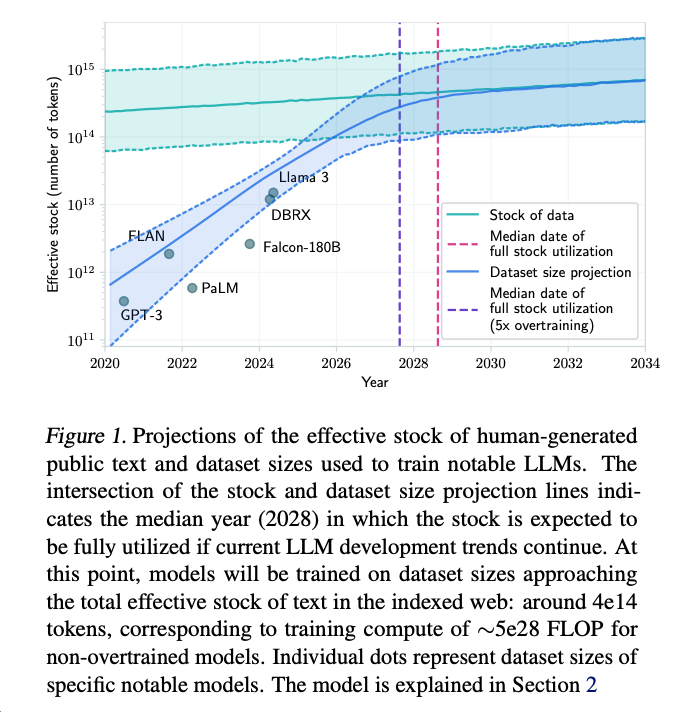
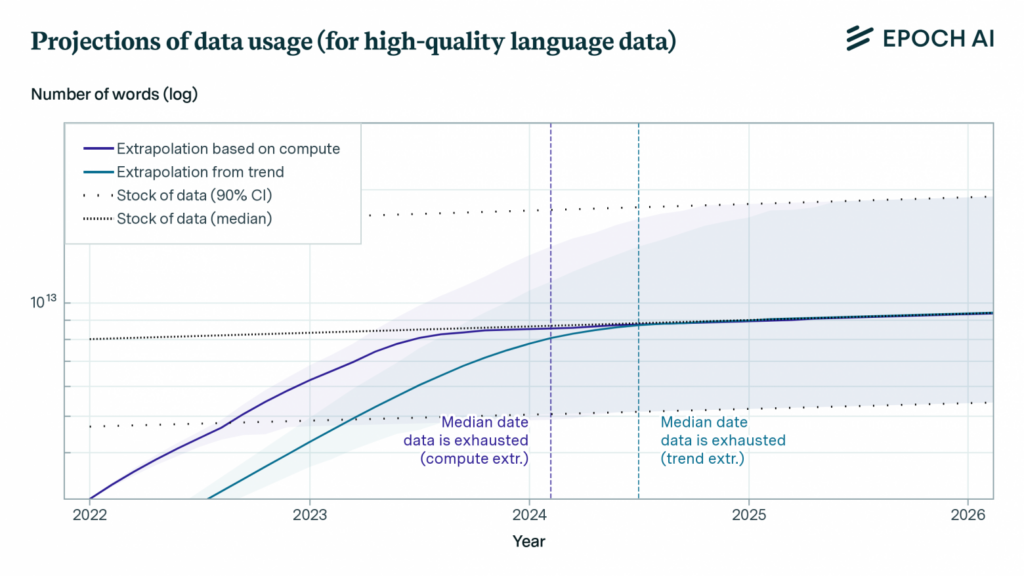
Ursprünglich prognostizierten Experten, dass der akute Mangel an hochwertigen Textdaten für das KI-Training bereits ab 2026 eintreten würde. Obwohl die Entwickler gelernt haben, die verfügbaren Informationen effizienter zu nutzen, wurde das Problem nicht gelöst, sondern lediglich für die nächsten 2-8 Jahre verschoben.
KI auf synthetischen Daten zu trainieren, also auf Texte, die von einer anderen KI erstellt wurden, ist mit erheblichen Problemen verbunden. Wie Nicholas Paperno, Forscher am Vector Institute for Artificial Intelligence, bildhaft feststellte, ist dies wie endloses Fotokopieren: Mit jedem neuen Durchlauf werden die Informationen verzerrt, verlieren an Klarheit und es kommt zu Interferenzen. Im Zusammenhang mit KI droht dies die Qualität der Systeme zu verringern, die Zahl der Fehler zu erhöhen und bereits bestehende Vorurteile zu verstärken.
Angesichts dieser Herausforderungen machen sich die Betreiber beliebter Plattformen wie Reddit und Wikipedia Gedanken über die Zukunft des KI-Trainings. Selena Dekelmann von der Wikimedia Foundation betont die Wichtigkeit, dass Menschen motiviert bleiben, selbst hochwertige Inhalte zu erstellen. Andernfalls könnte das Internet mit billigen und minderwertigen Inhalten gefüllt werden, die von künstlicher Intelligenz erstellt werden.
Prognose von Sam Altman
Sam Altman, Leiter von OpenAI, ist sich des Problems bewusst und schließt nicht aus, dass Unternehmen in Zukunft Menschen dafür bezahlen müssen, spezielle Datensätze für das KI-Training zu erstellen. Denn ohne einen ständigen Zustrom von “lebendigen” und aussagekräftigen Informationen droht die Entwicklung der künstlichen Intelligenz in eine Sackgasse zu geraten.
Zusammenfassend lässt sich sagen, dass das Problem des Mangels an menschlichen Texten für das KI-Training immer drängender wird. Es gibt noch keine eindeutige Lösung, aber die KI-Unternehmen müssen Maßnahmen ergreifen, um die Verfügbarkeit von Qualitätsdaten für die weitere KI-Entwicklung sicherzustellen.
Wir freuen uns darauf, Ihnen bei der Verarbeitung Ihrer Daten zu helfen! Dabei greifen wir auf unsere umfassende Erfahrung in den Bereichen Data Warehouse-Modellierung, Aufbau von Berichtssystemen in einer Cloud-Infrastruktur sowie dem Einsatz von maschinellem Lernen zur Lösung realer Geschäftsprobleme zurück.
Kostenlose Beratungstermine können ab sofort hier gebucht werden.