Mit der rasanten Entwicklung der generativen künstlichen Intelligenz (KI) und ihrer zunehmenden Anwendung in verschiedenen Bereichen, von der Automobilindustrie über die Medizin bis hin zu Bildungseinrichtungen und der Verwaltung, ist die Entwicklung von GPU Server von entscheidender Bedeutung geworden.
Dieser Artikel befasst sich mit den wichtigsten Komponenten, die bei der Wahl eines KI-Servers eine entscheidende Rolle spielen: die zentrale Recheneinheit (CPU und GPU) sowie die Grafikkarten (GPU). Die richtige Auswahl von CPUs und Grafikkarten ermöglicht es Ihnen, eine leistungsstarke Supercomputing-Plattform zu betreiben und KI-bezogene Berechnungen auf einem dedizierten oder virtualisierten (VPS) Server deutlich zu beschleunigen.
Wie Sie den richtigen Prozessor für Ihren KI Server wählen
Der Prozessor ist das “Gehirn” des Servers, der die Befehle des Benutzers entgegennimmt und die “Befehlszyklen” ausführt, die zu den gewünschten Ergebnissen führen. Ein wesentlicher Faktor für die Leistungsfähigkeit eines KI-Servers ist somit der Prozessor, der das Herzstück des Systems darstellt.
Viele Menschen erwarten einen Vergleich zwischen AMD- und Intel-Prozessoren. Tatsächlich stehen diese beiden Branchenführer an der Spitze der Prozessorproduktion. Intels Intel® Xeon® Prozessoren der fünften Generation (die sechste Generation wurde bereits angekündigt) und AMDs EPYC™ 8004/9004-Reihe markieren die Spitze der x86-basierten CISC-Prozessorentwicklung.
Wenn Sie nach hoher Leistung in Kombination mit einem ausgereiften und bewährten Ökosystem suchen, ist die Wahl von Spitzenprodukten dieser Hersteller die richtige Entscheidung. Bei einem begrenztem Budget können Sie auch ältere Versionen von Intel® Xeon® und AMD EPYC™ Prozessoren in Betracht ziehen.
Selbst ältere Desktop-CPUs von AMD oder Nvidia eignen sich gut als Einstieg in die KI, solange Ihre Arbeitslast keine große Anzahl von Kernen und begrenzte Multithreading-Fähigkeiten erfordert. In der Praxis ist die Wahl zwischen den CPU-Typen bei Sprachmodellen weniger relevant als die Wahl zwischen einem Grafikbeschleuniger oder der Menge des im Server installierten RAM.
Einige Modelle (z. B. 8x7B von Mixtral) können zwar Ergebnisse liefern, die mit der Rechenleistung von Tensor-Kernen von Grafikkarten auf der CPU vergleichbar sind, benötigen aber auch doppelt oder dreimal so viel Arbeitsspeicher wie bei einem CPU + GPU-Bündel. So kann ein Modell, das mit 16 GB RAM und 24 GB GPU-Videospeicher läuft, bis zu 64 GB RAM benötigen, wenn es nur auf der CPU ausgeführt wird.
Neben AMD und Intel gibt es noch weitere Optionen. Dazu gehören Lösungen, die auf der ARM-Architektur basieren, wie NVIDIA Grace™, das ARM-Cores mit proprietären NVIDIA-Funktionen kombiniert, oder Ampere Altra™.
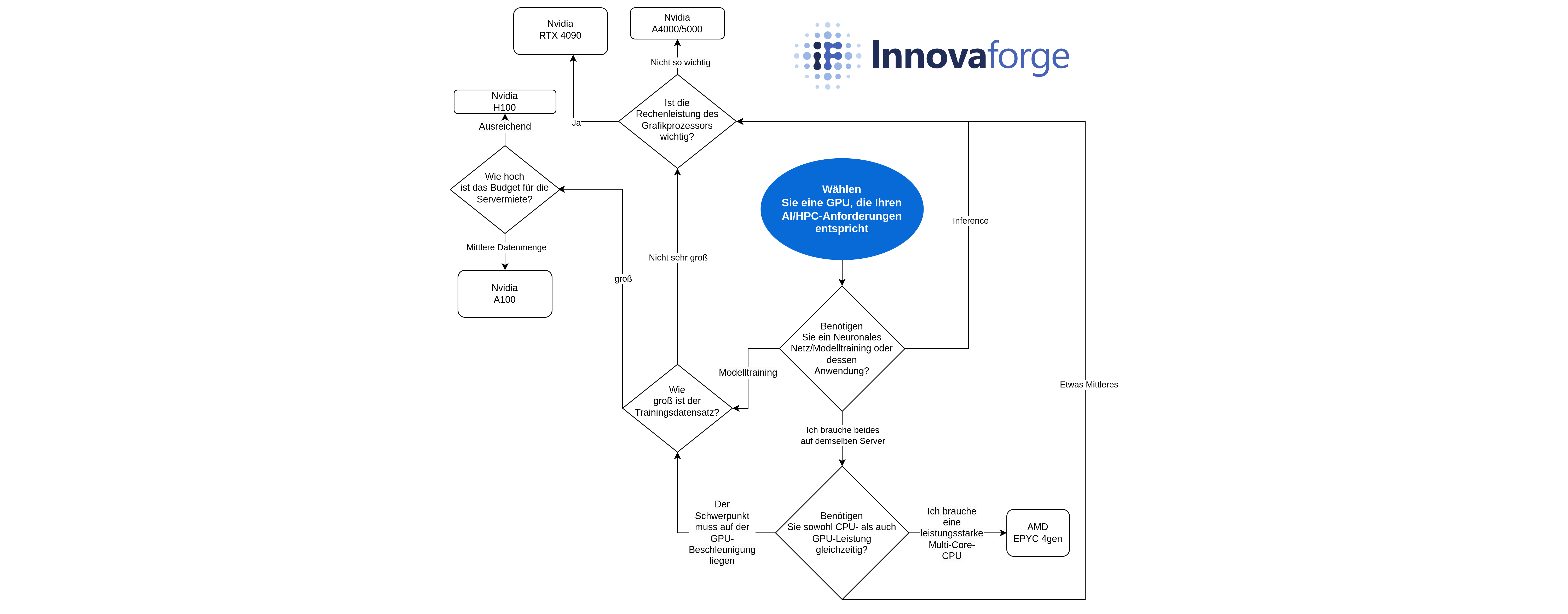
Wie Sie den richtigen Grafikprozessor (GPU) für Ihren GPU Server auswählen
Die Grafikverarbeitungseinheit (GPU) spielt eine entscheidende Rolle beim Betrieb eines GPU Server. Sie fungiert als Beschleuniger, der die Zentraleinheit (CPU) bei der Verarbeitung von Anfragen des neuronalen Netzes deutlich schneller und effizienter unterstützt. Der Grafikprozessor kann eine Aufgabe in kleinere Segmente aufteilen und diese mit Hilfe von parallelen Berechnungen oder speziellen Kernen gleichzeitig verarbeiten. Dieselben NVIDIA Tensor-Kerne liefern eine um Größenordnungen schnellere Leistung für 8-Bit-Gleitkommaberechnungen (FP8) in der Transformer Engine, Tensor Float 32 (TF32) und FP16 und zeichnen sich im High-Performance-Computing (HPC) aus.
Dieser Vorteil zeigt sich vor allem beim Training und weniger bei der Inferenz (Einsatz des neuronalen Netzes), da dieser Prozess beispielsweise bei Modellen mit FP32 mehrere Wochen oder sogar Monate dauern kann.
Um die Auswahl einzugrenzen, müssen Sie die folgenden Fragen beantworten:
- Wird sich die Art meines KI-Arbeitsaufkommens im Laufe der Zeit ändern? Die meisten der heutigen Grafikprozessoren sind auf sehr spezifische Aufgaben ausgelegt. Ihre Chip-Architektur mag für bestimmte Entwicklungs- oder KI-Anwendungen geeignet sein, und neue Hardware- und Software-Lösungen könnten die vorherige Generation von GPUs in den nächsten zwei bis drei Jahren nicht mehr wettbewerbsfähig machen.
- Werden Sie hauptsächlich mit KI-Training oder Inferencing (Verwertung) beschäftigt sein? Diese beiden Prozesse liegen allen aktuellen Iterationen der KI mit begrenzten Speicherbudgets zugrunde.
- Während des Trainings nimmt ein KI-Modell große Mengen von Big Data mit Milliarden oder sogar Billionen von Parametern auf. Es passt die “Gewichte” seiner Algorithmen so lange an, bis es konsistent das richtige Ergebnis liefert.
- Während der Inferenz stützt sich die KI auf das “Gedächtnis” ihres Trainings, um auf neue Eingaben in der realen Welt zu reagieren. Beide Prozesse sind rechenintensiv, weshalb GPU-Karten und Erweiterungsmodule installiert werden, um die Prozesse zu beschleunigen.
Für das Training künstlicher Intelligenz sind GPUs mit speziellen Kernen und Mechanismen ausgestattet, die diesen Prozess optimieren können.
Der NVIDIA H100 mit 8 GPU-Kernen kann beispielsweise eine Leistung von mehr als 32 Petaflops beim Deep Learning in FP8 erbringen. Jeder H100 enthält Tensorkerne der vierten Generation, die den neuen FP8-Datentyp verwenden, sowie die Transformer Engine zur Optimierung des Modelltrainings. NVIDIA hat kürzlich die nächste Generation seiner B200-GPUs vorgestellt, die noch leistungsfähiger sein wird.
Eine gute Alternative zu AMD-Lösungen wäre der AMD Instinct™ MI300X. Sie verfügt über einen riesigen Speicher und einen hohen Datendurchsatz, was für generative KI im Inferenzmodus wie große Sprachmodelle (LLMs) wichtig ist. AMD behauptet, dass seine GPUs 30 Prozent effizienter sind als die Lösungen von NVIDIA, obwohl sie bei der Software den Kürzeren ziehen.
Wenn Sie bereit sind, etwas Leistung zu opfern, um Ihr Budget zu schonen, oder wenn der Datensatz, mit dem Sie KI trainieren wollen, nicht so groß ist, lohnt es sich, andere Angebote von AMD und NVIDIA in Betracht zu ziehen. Für Inferenzmodi oder wenn kein Bedarf an ununterbrochenem Volllastbetrieb rund um die Uhr besteht, sind Nvidia RTX 4090- oder sogar RTX 3090-basierte “Consumer”-Lösungen für das Training geeignet.
Wenn Sie auf der Suche nach einer stabilen Langzeitberechnung für das Modelltraining sind, könnten Sie die RTX A4000- oder A5000-Grafikkarten von Nvidia in Betracht ziehen. Während die H100 am PCIe-Bus eine leistungsfähigere Lösung sein kann (60-80 % mehr Leistung je nach Aufgabe), ist die RTX A5000 erschwinglicher und für einige Aufgaben geeignet (z. B. für die Arbeit mit 8x7B-Modellen).
Zu den exotischeren Lösungen für Inferencing gehören AMD Alveo™ V70 Karten, NVIDIA A2/L4 Tensor Core, Qualcomm® Cloud AI 100. In naher Zukunft bereiten sich AMD und NVIDIA darauf vor, Intel mit Gaudi 3 GPUs auf dem KI-Trainingsmarkt zu verdrängen.
Zusammenfassend lässt sich sagen, dass GPU Server mit Intel Xeon- und AMD Epyc-Prozessoren sowie NVIDIA-GPUs unter Berücksichtigung der Softwareoptimierung für HPC und KI zu empfehlen sind. Für KI-Inferenz können Sie GPUs von RTX A4000/A5000 bis RTX 3090 verwenden, und für Training und multimodale neuronale Netzwerke sollten Sie Lösungen von RTX 4090 bis H100 einplanen.
Wenn Sie weitere Hilfe bei der Auswahl der richtigen Hardware für Ihre Services benötigen oder generell mehr über die Anwendung von Advanced Analytics und Machine Learning erfahren möchten, dann kontaktieren Sie uns gerne für ein kostenloses Beratungsgespräch!